
About
I am a Data Engineer with 2.5 years of hands-on experience in creating robust and scalable big data systems. My work revolves around automating analytical processes and delivering critical data products that drive business decisions.
In my professional journey, I have excelled in designing, developing, and managing both batch and real-time streaming data pipelines. My expertise ensures the timely availability of analytical solutions, leveraging an extensive array of big data technologies in both on-premises and cloud-native environments. This experience has solidified my skills in problem-solving, distributed processing, data modeling, data analysis and visualization, data governance, and automating ETL flows using data orchestration tools. Additionally, I have a proven track record in deploying machine learning models.
I thrive on tackling challenging projects as they provide ample learning opportunities, contributing to both my technical and professional growth. My guiding philosophy is: “The World requires change. Change requires narrative. Narrative requires data.” This belief fuels my quest for knowledge and drives my passion for data engineering.
Beyond the industry, I spent 1.5 years as a Graduate Researcher, focusing on resource optimization using Reinforcement Learning. Currently, I am exploring online methods for adjusting the weights of large language models (LLMs) during training. My curiosity has also led me to dabble in IoT, home automation, and computer vision projects.
Further, I love sharing my knowledge and contributing to the data engineering community through my technical writing. I have authored various Medium articles talking about my learning and experiences. Additionally, I serve as an Editor for Data Engineer Things publication which is dedicated to curating original learning resources for data engineers on Medium platform.
Outside my professional life, I enjoy working out in the gym, watch documentaries, dance and explore nature and big time foodie.
Work Experience
YahooMountain View, California
Data Engineer InternMay 2023 - August 2023
Yahoo is a global media and tech company providing various services, including a web portal, search engine, news, email, and advertising services. During the internship, I was part of data plaforms team tasked with user-profiling and I worked on building core datasets, enabling data-driven decision-making on Yahoo's product improvements.
- Architected AWS QuickSight dashboards, improving cloud security & operational efficiency, improved cost utilization & data visibility.
- Developed an AWS SNS-based system for real-time data anomaly alertsin S3 buckets, boosting data integrity and quality check by 25%.
- Automated data ingestion & optimized API queries to retrieve user data from Gemini, achieved 96% accuracy
- Developed a BERT-based NLP model chatbot, reducing internal data query search time by 30%.
- Skills: AWS QuickSight, Terraform, Airflow, DynamoDB, Python, Streamlit, BERT, SNS
Texas A&MCollege Station, Texas
Machine and Cloud researcherSeptember 2022 - Present
The Learning and Emerging Networked Systems (LENS) at Texas A&M aims to conduct analytical and experimental research in machine learning and reinforcement learning with networked systems applications.For 1.5 years, I worked as researcher under the resource optimization department. We are Trying to disrupt the field of orchestration and autoscaling system for allocating resources to microservice applications. Using zeroth gradient approaches and reinforcement learning methods to achieve these objectives.
- Optimized data processing pipelines for a social media microservice application, achieving a 12% reduction in latency.
- Utilized Docker for efficient containerization and integrated real-time data monitoring with Jaeger. Used reinforcement learning and policy gradient strategies for effective resource management, enhancing system scalability to exceed industry standards by 14%.
- Extended microservices with Spring REST APIs, using Docker for containerization, Kubernetes for orchestration, and Nginx/Apache Tomcat for load balancing and secure token-based authentication.
- Integrated real-time monitoring and ETL pipelines, reducing data processing time by 40%
- Skills: Docker, Kubernetes, Spring, Nginx, Apache Tomcat, Spark, Telemetry, Grafana, Jaeger
Texas A&MCollege Station, Texas
Machine and Data EngineerSeptember 2022 - Present
- Deployed machine learning models for plant stress detection, achieving 95% IOU with YOLOv8.
- Architected full-stack web service for heat risk assessment, integrated databases, containerized and deployed it
- Integrated MLOps pipelines for automation and scalability.
- Skills: PyTorch, Django, Flask Docker, AWS SageMaker, NoSQL(MongoDB, DynamoDB), MySQL, Airflow, ECS.
- Skills: Docker, Kubernetes, Spring, Nginx, Apache Tomcat, Spark, Telemetry, Grafana, Jaeger
Redbus (Bus & Train Tickeing Application)Bengaluru, India
Data EngineerJuly 2020 - July 2022
RedBus is an Multi-National online bus ticketing platform that facilitates the booking of bus tickets and other related services across multiple cities and operators. I worked for two years as a Data Engineer. I was part of the data lake team where i contributed in creation of data lake for unified view, developed ETL pipelines for inventory management, sales, payments & Marketing (CRM channels). Additionally developed dashboards & websites to drive the adoption of premium services offered to operators.
- Developed and scaled 40+ ETL pipelines with AWS, Apache (NiFi, Kafka, Spark, Storm, Hadoop), processing 10M events daily. Optimized batch processing with Spark (8M+ records), saving 2 hours runtime.
- Migrated legacy systems to AWS, creating a data lake with Redshift (15% retrieval time reduction, 25% storage cost savings). Warehousing (Redshift). Developed dashboards tailored to business needs. Worked with crossfunctional team from India and Singapore.
- Engineered a Marketing and Sales Data Analysis Platform, integrating hot and cold data storage (PostgreSQL, AWS S3) and dynamic dashboards (Tableau, Redash), leading to a 2.5% increase in customer acquisition and an 8% rise in quarterly transactions. Under this initiative, built a real-time user interaction analytics pipeline (Kinesis, DynamoDB) processing 400K mobile app events hourly, delivering user engagement insights.
- Built real-time pipelines for user interaction data on Android and payment analytics, processing 400K events hourly and reducing failure notification time by 80%, using Kinesis, Lambda, DynamoDB, S3, SNS, Kafka, and Spark-stream.
- Architected data-driven rating system for 3,500 bus operators across India and Singapore, implementing ETL pipeline with cold/hot storage in Redshift/DynamoDB. Developed 3NF-compliant models, Tableau dashboards, and Django REST API-powered web app. Resulted in 20% increase in Premium service adoption among operators
- Deployed surge pricing & anomaly detection models using AWS SageMaker (CI/CD with Kubeflow, Jenkins, GitHub Actions). Achieved 25% faster model updates, leading to $1M revenue increase & 40% fraud detection improvement.
InternJan 2020 - June 2020
During my internship i worked on wide array of IoT,NLP, computer-vision based projects as i was part of sole R&D team.
- Developed an IoT - computer vision based solution for real-time bus footfall tracking, resulting in a 17% reduction in pilferage.
- Created onboard diagnostics system to capture & display bus performance. Reduced daily fuel consumption by 500 gallons.
- Created an Alexa application & streamlined ticketing for voice-command bus ticket bookings, serving 20000 customers.
Electronics Cooperation of India LimitedHyderabad, India
InternJune 2018 - August 2018
Electronics Corporation of India Limited (ECIL) is a Government of India enterprise that develops and manufactures electronic products for the defense, nuclear, and industrial sectors.
- Designed a dashboard using grafana and JSON-API to visualize the load characteristics of a local electric grid.
Education
Texas A&M UniversityCollege Station, Texas
Master of Science in Computer EngineeringAugust 2022 - Dec 2024
Relevant Coursework: Mathematics for Signal Processing,Data Analytics, Machine Learning, Database Systems, Distributed Systems & Cloud Computing, Operating Systems, Parallel Computing
Awards: Graduate Merit Departmental Scholarship, 3rd place Texas A&M Institute of Data Science Competition.
JSS Science & Technology UniversityMysore, India
Bachelor of Engineering in Electronics and Communication EngineeringAugust 2016 - September 2020
Relevant Coursework: Software Engineering, Data Structures and Algorithms, Operating Systems, Linear Algebra and applications, Computer Networks
Organizations: AeroJC (Aviation Club Head), part of IEEE student org
Projects
Explore my data engineering and Machine Learning projects in this section.
G Maps GPT Code
Tech Stack: Python, Flask, Neon Tech (Serverless PostgreSQL), OpenAI GPT Models, LangChain, LangGraph, Google Maps API, Chart.js, ReportLab
G Maps GPT is an intelligent assistant for querying and analyzing condominium data in Miami, designed for non-technical users like real estate agents and investors. It offers a natural language interface to access condo sales, market trends, and building data, integrates Google Maps for location-based queries, and visualizes insights using charts, graphs, and interactive maps. Features include PDF report generation, spelling correction using vector embeddings, serverless database scaling, and a curated prompt to reduce hallucinations.
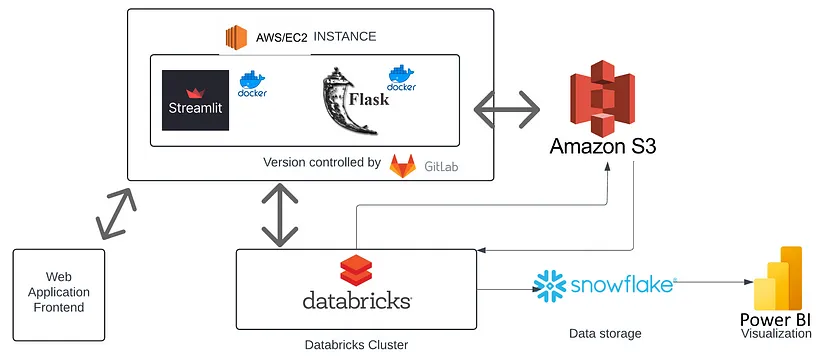
Real Time Traffic Video stream analysis Code
Tech Stack: python, AWS, Databricks, Streamlit, Flask, OpenCV, Snowflake, PowerBI
A full-stack Real-Time Video Stream Analytics application utilizing Streamlit, Flask, Apache Spark on Databricks, and AWS, enhanced by CI/CD practices, to perform and visualize advanced object detection and counting from vehicular traffic videos

Deeplearning Image classifier model deployment Code
Tech Stack: Flask, Keras, MLflow, DVC, AWS (S3, ECR, EC2), Docker
A comprehensive MLOps pipeline for a plant leaf health classification web application, showcasing data versioning, experiment tracking, CI/CD, containerization, and cloud deployment.

AWS ETL pipeline that does Youtube data analysis Code
Tech Stack: AWS, Python, Spark
I designed and implemented a comprehensive data architecture leveraging AWS services. By utilizing S3 for storage, Lambda, Spark, and Athena, I built an end-to-end data pipeline to transform and analyze a YouTube trending videos dataset with over 1 million rows. I orchestrated the ETL workflow in Glue Studio and created QuickSight dashboards to visualize key metrics.

Real time sentiment analysis Code
Tech Stack: Flask, Spark, Kafka, Airflow, AWS S3, glue, Quicksight, docker
A datapipeline that in real time stream and batch takes the data from users input from a web application. The data is subjected to data processing and sentiment analysis. The web application is made by Flask.

Data pipeline for healthcare industry Code
Tech Stack: Amazon S3, PostgresSQL, MySQL, RDS, Spark, Power BI
The Healthcare Data Pipeline project creates a unified data storage solution for large healthcare datasets using Spark on EMR and S3, with Power BI dashboards for visualization, enabling efficient data ingestion, cleansing, transformation, and insightful analysis.

Predicting large scale wildfire Code
Tech Stack: Deep Neural Networks, AWS, SHAP Analysis, NLP
PyTorch-based neural network to predict wildfires with 95% accuracy, utilizing SHAP analysis and NLP techniques for early detection through social media analysis, enhancing data-driven emergency response strategies.

Taxi Data analytics and ETL pipeline Code
Tech Stack: GCP Storage, Python, Compute Instance, Mage Data Pipeline Tool, BigQuery, and Looker Studio.
We extract data from a web api and automate the ETL using Mage and store the data in Big Query and dashboard made using Looker is built on top of that.

Blog
Explore my technical articles on data engineering in this section. I am part of the group "Data Engineer Things" that has 32K followers on Linkedin



Skills
Here is a snapshot of data engineering skills that I bring to the table.
Programming Languages
- Python
- Java
- Scala
- SQL
- C++
Big Data
- Snowflake
- Hadoop
- Spark
- Kafka
- Airflow
- Storm
Databases
- MySQL
- PostgreSQL
- NoSQL (MongoDB, Cassandra)
- Oracle
Visualization and Other Tools
- AWS Quicksight
- Tableau
Cloud and Containers
- AWS (S3, EC2, Glue, Athena, Lambda, EMR, IAM)
- Azure (Data Factory, Data Lake, Databricks, Synapse Analytics)
- Docker
Certifications
- AWS data engineering associate
- Oracle Database associate
- Data Manipulation with Python - DataCamp
Devops Tools
- Git
- Jira
- Cloud Formation
- Terraform
- Jenkins
Contact
Feel free to reach out to me on the details mentioned below.
Write to me: prathikvijaykumar@tamu.edu